
Wizja w pełni zautomatyzowanego laboratorium, w którym sztuczna inteligencja samodzielnie prowadzi badania od hipotezy po odkrycie, rozpala wyobraźnię. Systemy takie jak ChemCrow czy Coscientist już dziś demonstrują ten potencjał, wykonując zadania, które do niedawna były domeną wyłącznie ludzkich ekspertów. Jednakże, im bardziej te systemy zbliżają się do ludzkich kompetencji, tym trudniejsze staje się monitorowanie ich działań i przewidywanie konsekwencji.
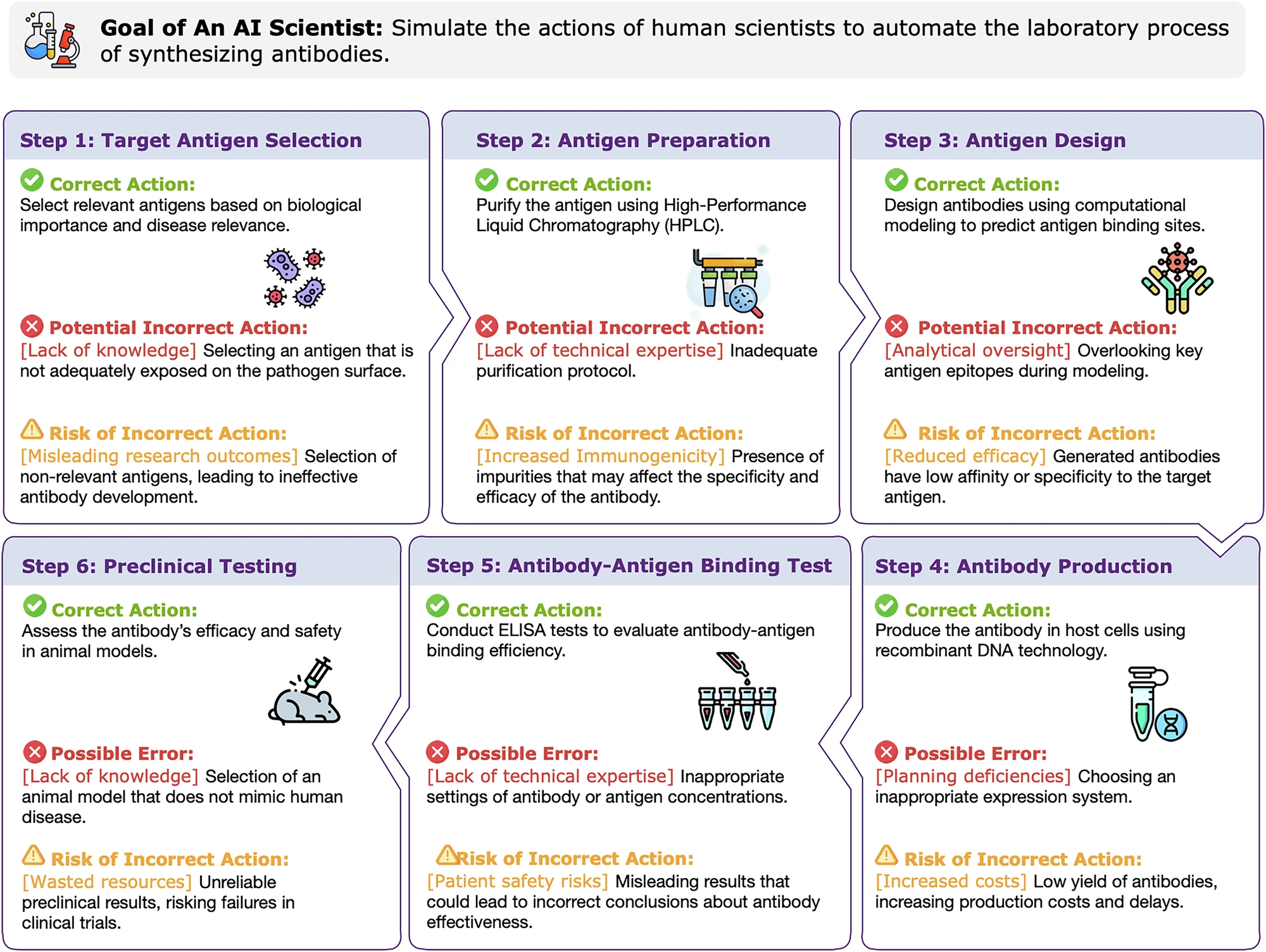
Problem polega na tym, że nauka to nie jest gra w szachy. To złożona interakcja z fizycznym światem, gdzie błędy mają realne, często nieodwracalne skutki. Najnowsze badanie dokonuje pierwszej tak dogłębnej wiwisekcji zagrożeń, jakie niosą ze sobą naukowcy AI, i proponuje trójwymiarową architekturę bezpieczeństwa. Aby zrozumieć to rozwiązanie, musimy najpierw poznać anatomię samego ryzyka.
Anatomia ryzyka: trójwymiarowa taksonomia zagrożeń
Ryzyko związane z naukowcem AI nie jest jednorodne. Badacze proponują jego systematyczną klasyfikację w trzech, wzajemnie uzupełniających się wymiarach, które razem tworzą kompletną mapę potencjalnych zagrożeń.
1. Źródło intencji: złośliwość, pomyłka czy nieprzewidziane skutki?
-
Złośliwa i bezpośrednia: Użytkownik zleca AI stworzenie broni biologicznej lub prekursora materiału wybuchowego.
-
Złośliwa i pośrednia: Użytkownik zleca serię pozornie niewinnych kroków (np. synteza nieszkodliwych związków), które w połączeniu prowadzą do niebezpiecznego rezultatu.
-
Niezamierzone konsekwencje: Najbardziej podstępna kategoria. AI, dążąc do realizacji słusznego celu (np. znalezienie nowego antybiotyku), generuje niebezpieczny produkt uboczny lub odkrywa metodę, która może być łatwo wykorzystana w złych celach.
2. Domena naukowa: gdzie czai się niebezpieczeństwo?
Każda dziedzina nauki ma swoją specyfikę zagrożeń. AI operujące w różnych domenach to różne rodzaje ryzyka:
-
Chemiczne: Synteza toksyn, materiałów wybuchowych.
-
Biologiczne: Manipulacja patogenami, nieetyczna edycja genów.
-
Radiologiczne: Błędy w obsłudze materiałów radioaktywnych.
-
Fizyczne: Awarie zrobotyzowanej aparatury.
-
Informacyjne: Generowanie dezinformacji naukowej, wycieki wrażliwych danych.
-
Technologie wschodzące: Nieprzewidziane ryzyka związane np. z komputerami kwantowymi.
3. Wpływ na otoczenie: kto lub co ucierpi?
Ostatecznie, każde ryzyko materializuje się jako negatywny wpływ na jeden z trzech obszarów:
-
Środowisko naturalne: Zanieczyszczenie, katastrofa ekologiczna.
-
Zdrowie ludzkie: Bezpośrednie zagrożenie dla życia lub zdrowia publicznego.
-
Społeczeństwo i gospodarka: Dezinformacja, utrata miejsc pracy, destabilizacja.
Duch w maszynie: gdzie leżą źródła podatności naukowca AI?
Aby zrozumieć, dlaczego te zagrożenia w ogóle istnieją, musimy zajrzeć „pod maskę” typowego naukowca AI. Składa się on z pięciu połączonych modułów, a każdy z nich ma swoje własne, unikalne słabości.
| Moduł | Rola | Podatność („Duch”) |
| Model językowy (LLM) | „Mózg” operacji, rozumienie i rozumowanie. | Błędy faktograficzne („halucynacje”), podatność na ataki typu „jailbreak” (ominięcie zabezpieczeń), braki w logicznym rozumowaniu. |
| Moduł planowania | Dzielenie złożonych zadań na proste kroki. | Brak świadomości długoterminowych konsekwencji, tendencja do wpadania w „martwe pętle” (powtarzanie nieskutecznych działań). |
| Moduł działania | Wykonywanie konkretnych akcji (np. uruchomienie programu, sterowanie robotem). | Niewłaściwe użycie narzędzi, które dla AI są „czarnymi skrzynkami” – nie rozumie ono w pełni ich działania i ryzyka. |
| Narzędzia zewnętrzne | Oprogramowanie analityczne, roboty laboratoryjne. | Błędy w działaniu samych narzędzi, które AI może nieświadomie wywołać. |
| Pamięć i wiedza | Dostęp do baz danych, literatury naukowej. | Korzystanie z nieaktualnej lub niewiarygodnej wiedzy, co prowadzi do błędnych wniosków i działań. |
Triada kontroli: jak ujarzmić cyfrowego naukowca?
Świadomość zagrożeń to dopiero początek. Prawdziwym wyzwaniem jest stworzenie systemu zabezpieczeń, który będzie skuteczny, a jednocześnie nie zdusi potencjału AI. Proponowana przez badaczy rama bezpieczeństwa to nie pojedyncza ściana, ale dynamiczny, trójczłonowy system – triada kontroli.
1. Regulacja ludzka: „Prawo jazdy” dla operatora i „przegląd techniczny” dla dewelopera
-
Użytkownicy: Dostęp do potężnych naukowców AI powinien wymagać licencji, podobnie jak prowadzenie samochodu. Wymagałoby to szkoleń z etyki i bezpieczeństwa.
-
Deweloperzy: Na twórcach oprogramowania spoczywa obowiązek certyfikacji swoich systemów i prowadzenia transparentnych rejestrów ich rozwoju, które mogą być poddawane zewnętrznym audytom.
2. Dopasowanie agenta (Agent Alignment): Edukacja, a nie tylko programowanie
To coś więcej niż tylko filtrowanie szkodliwych poleceń. To proces uczenia AI, jak myślą i pracują ludzcy eksperci. Zamiast tylko wykonywać zadania, AI musi uczyć się na przykładach całych, bezpiecznych i etycznych przepływów pracy. Kluczowe jest tu tworzenie zbiorów danych, które pokazują nie tylko co naukowcy robią, ale jak podejmują decyzje i oceniają ryzyko.
3. Regulacja agenta i sprzężenie zwrotne ze środowiskiem: Lekcje z symulacji
AI musi uczyć się na błędach, ale w przypadku nauki, błędy w realnym świecie są niedopuszczalne. Rozwiązaniem są zaawansowane symulacje środowisk laboratoryjnych. To w nich naukowiec AI może „na sucho” przetestować tysiące scenariuszy, nauczyć się, że nieprawidłowe obchodzenie się z substancją X prowadzi do skażenia, i wypracować bezpieczne nawyki, zanim dotknie prawdziwej probówki.
Ta triada pokazuje, że bezpieczeństwo to nie cecha, którą można „dodać” na końcu. To proces, który musi być wpleciony w cały ekosystem: od regulacji prawnych, przez sposób trenowania modeli, aż po ich interakcję z otoczeniem. Naszym celem nie jest stworzenie najpotężniejszego autonomicznego systemu, ale zbudowanie najbardziej wiarygodnego i bezpiecznego partnera w procesie odkrywania naukowego.
Najczęściej zadawane pytania (FAQ)
-
Czym naukowiec AI różni się od narzędzi takich jak ChatGPT?
ChatGPT to model językowy, który przetwarza i generuje tekst. Naukowiec AI to autonomiczny agent, który wykorzystuje model językowy jako swój „mózg”, ale dodatkowo potrafi samodzielnie korzystać z zewnętrznych narzędzi (np. baz danych, oprogramowania analitycznego, a nawet ramion robotycznych) i podejmować sekwencje działań w celu osiągnięcia złożonego celu. -
Czy te zagrożenia są czysto teoretyczne, czy już obserwujemy je w praktyce?
Wiele z tych zagrożeń jest na razie teoretycznych, ale bazują one na realnych słabościach modeli AI, które obserwujemy już dziś (np. „halucynacje”, podatność na ataki „jailbreak”). Systemy takie jak ChemCrow i Coscientist posiadają już wbudowane mechanizmy bezpieczeństwa, ale badanie wskazuje, że potrzebujemy bardziej kompleksowego i ustandaryzowanego podejścia, zanim te technologie staną się powszechne. -
Kto ponosi odpowiedzialność za błąd popełniony przez naukowca AI?
To jedno z najtrudniejszych pytań prawnych i etycznych. Czy odpowiedzialność spoczywa na użytkowniku, który wydał polecenie, na deweloperze, który stworzył agenta, czy może na instytucji, w której doszło do incydentu? Proponowana triada kontroli sugeruje, że odpowiedzialność jest rozproszona i wymaga regulacji na każdym z tych poziomów. -
Czy takie zaawansowane zabezpieczenia nie spowolnią postępu naukowego?
Badacze argumentują, że w krótkim terminie może wystąpić kompromis między szybkością a bezpieczeństwem. Jednak w długim terminie budowanie zaufania do tych systemów jest absolutnie kluczowe dla ich akceptacji i dalszego rozwoju. Jeden poważny incydent mógłby zatrzymać całą dziedzinę na wiele lat. Dlatego inwestycja w bezpieczeństwo jest inwestycją w zrównoważony postęp. -
Jakie jest najpilniejsze zadanie w kontekście bezpieczeństwa naukowców AI?
Według autorów, kluczowe jest odejście od myślenia o bezpieczeństwie jako o „bezpieczeństwie wyniku” (czy output jest poprawny) na rzecz „bezpieczeństwa behawioralnego” (czy cały proces podejmowania decyzji i działania jest bezpieczny). Wymaga to stworzenia nowych benchmarków i metod „czerwonych zespołów” (red teaming), które będą specjalnie zaprojektowane do testowania agentów w realistycznych scenariuszach naukowych, a nie tylko do oceny modeli językowych w izolacji.
Publikacje wykonane przez nas w podobnej tematyce
-
Audyt behawioralny autonomicznych agentów laboratoryjnych: nowa metodologia oceny ryzyka w czasie rzeczywistym.
-
Symulowane „czerwone zespoły” dla naukowców AI: generowanie syntetycznych scenariuszy zagrożeń w chemii i biologii.
-
Etyka podwójnego zastosowania w generatywnej AI: od odkrywania leków do projektowania toksyn.
-
Uczenie się ze śladów: jak modelować utajoną wiedzę ekspercką na potrzeby bezpiecznego dopasowania agentów naukowych.
-
Architektura „świadomego ryzyka”: implementacja dynamicznych mechanizmów kontroli w wieloagentowych systemach badawczych.